昨天我們談到random forest 的起源,原理與步驟:
尚未閱讀過的同學,可以從上一篇的連結,點閱一下昨日的前情提要,之前提過就不在贅述。
今明兩天我們要學習的目標:
詳談random forest 的步驟:
random forest 的程式碼:
再談random forest的步驟:
1.首先從datasets以隨機「自助」bootstrap,(未「bootstrap」),的方式取出n個樣本。
2.從「n樣本中」推導出「decision tree」,並且對每一個node :
a.隨機採用取出不放回no replacement,(未「no replacement」)選擇d個特徵。
b.依據objective function 找出最佳方式,用特徵分割該node。
3.將1~2重複k次
4.總結所有「decision tree」的預測,並且多數決majority voting方式,來指定target。
上面所說的 bootstrap,指得是隨機從datasets以取出放回replacement,(未「replacement」),就是取出來的樣本可以重複取,可能取出的次數會超過一次以上,或是一次,或0次。
對n樣本採用隨機no replacement 取出d個特徵,這裏的no replacement,由以上的 replacement,同理可推,每個樣本最多取出一次。
依據objective function 找出最佳方式,也是就是day7所說的讓電腦經由提供的資料猜測是男是女的
information gain,第一層的information gain是是否大於180公分,第二層的information gain是是否大於80公斤。
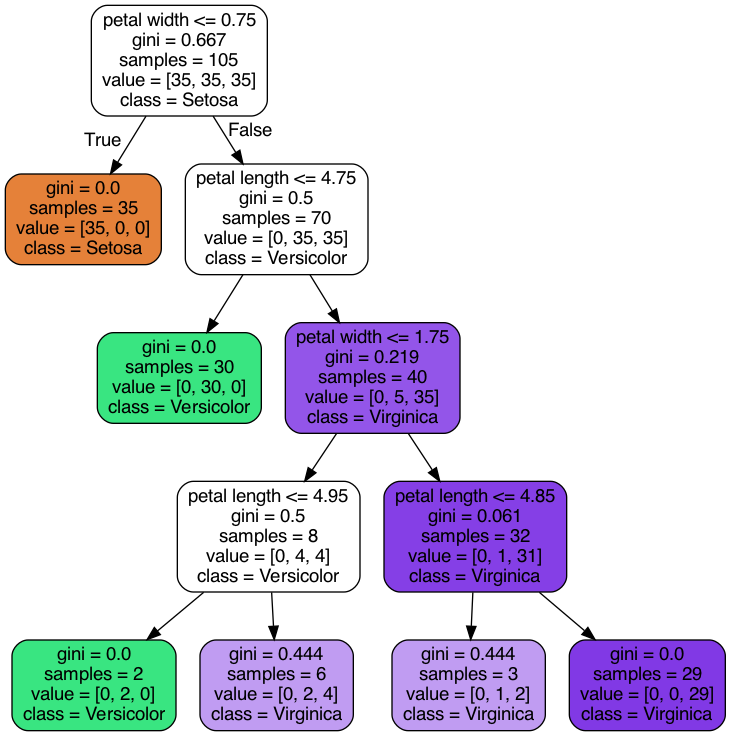
再舉我們以花朵分類做例子,如圖:
第一層infomation gain是花瓣寬度是否小於等於0.75,第二層infomation gain花瓣長度是否小於等於4.75.
最後的步驟則是匯總所有decison tree的預測,並且以majority voting 票數最高的來決定類別的class,所謂的類別就是物種,物品,也就是我們day3求是男生還是是女生的學生。學生就稱為類別。這個概念是從程式設計的物件導向而來的,世上所有你所看到的車子,防子,行道樹,都可以抽象化成類別class,就是物件導向的基本單位。


 iThome鐵人賽
iThome鐵人賽